Getting our hands dirty
As a field, machine learning is both expansive and mathematically complex. From deriving simple linear relationships via regression analysis to finding clusters of data points in an N-dimensional space; statistical and machine learning techniques can take years to fully master. However, given the short time available in this course, we will take the simpler approach of demonstrating several commonly used approaches in order to both introduce the fundamental concepts in machine learning and the methodology we will use in RStudio to apply these concepts to actual data. For the latter, we will use the standard machine learning library in R, which is the Caret Package.
We will demonstrate the four main tasks of machine learning: classification, regression, dimensional reduction, and clustering. Note that this module is simply an introduction to these topics, we will explore these and other areas in more detail throughout this course. Finally, we will discuss how to persist machine learning models.
Set up
Make sure you have the caret package installed.
install.packages("caret")
Run your libraries
The first steps in any data analytics effort, once the business goal has been defined, are to understand and prepare the data of interest. For example, the Cross Industry Standard Process for Data Mining or (CRISP-DM) starts with the Business Understanding step, immediately followed by the Data Understanding and Data Preparation steps. For machine learning analyses, these latter two steps require loading the data into our notebook, exploring the data either systematically or in a cumulative sense to understand the typical features for different instances. We also can generate descriptive statistical summaries and visualizations, such as a pair plot, to understand the data in full. Finally, we will need to clean the data to properly account for missing data, data that are incomplete or formatted incorrectly, or to generate meta-features (such as a date-time) from existing features.
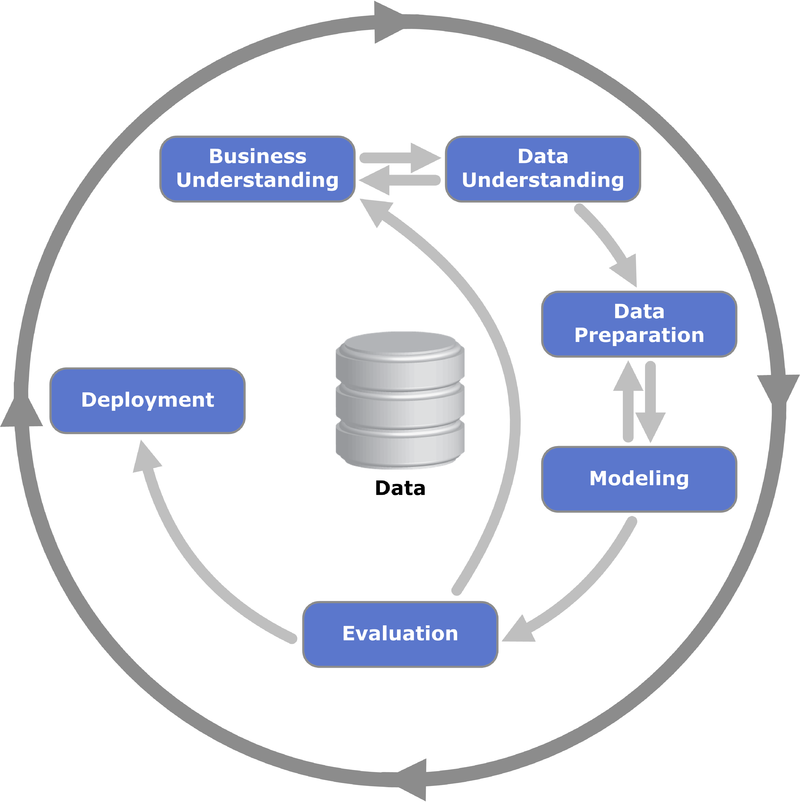
For this module, we will focus on a single, simple data set, the standard Iris dataset, which is included by default. Note that given a data set, such as the Iris data, we have rows, which correspond to different instances (e.g., different flowers), and columns, which correspond to different features of the instances (e.g., different measurements of the flowers). To understand the data, we first load this data into RStudio, before looking at several instances from the data. Next, we will group the data by species to explore cumulative quantities, before extracting a statistical summary of the entire data set. Finally, we will generate a pair plot to visually explore the data. Since this data has already been cleaned (and only consists of four features) we will not need to perform additional tasks.
Load the data
#load the data
iris<-iris
The data set consists of 150 total measurements of three different types of Iris flowers, equally divided between three classes: Iris setosa, Iris versicolor, and Iris virginica. Before proceeding, we can examine the DataFrame that contains these data to view typical instances, to see a cumulative summary, and a brief statistical summary.
#examine the top 5 rows
head(iris,5)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa#view the whole dataset
knitr::kable(iris)%>%
kableExtra::kable_styling("striped")%>%
kableExtra::scroll_box(width = "100%",height="300px")
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 5.0 | 3.4 | 1.5 | 0.2 | setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | setosa |
| 4.9 | 3.1 | 1.5 | 0.1 | setosa |
| 5.4 | 3.7 | 1.5 | 0.2 | setosa |
| 4.8 | 3.4 | 1.6 | 0.2 | setosa |
| 4.8 | 3.0 | 1.4 | 0.1 | setosa |
| 4.3 | 3.0 | 1.1 | 0.1 | setosa |
| 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 5.7 | 4.4 | 1.5 | 0.4 | setosa |
| 5.4 | 3.9 | 1.3 | 0.4 | setosa |
| 5.1 | 3.5 | 1.4 | 0.3 | setosa |
| 5.7 | 3.8 | 1.7 | 0.3 | setosa |
| 5.1 | 3.8 | 1.5 | 0.3 | setosa |
| 5.4 | 3.4 | 1.7 | 0.2 | setosa |
| 5.1 | 3.7 | 1.5 | 0.4 | setosa |
| 4.6 | 3.6 | 1.0 | 0.2 | setosa |
| 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 5.0 | 3.0 | 1.6 | 0.2 | setosa |
| 5.0 | 3.4 | 1.6 | 0.4 | setosa |
| 5.2 | 3.5 | 1.5 | 0.2 | setosa |
| 5.2 | 3.4 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| 4.8 | 3.1 | 1.6 | 0.2 | setosa |
| 5.4 | 3.4 | 1.5 | 0.4 | setosa |
| 5.2 | 4.1 | 1.5 | 0.1 | setosa |
| 5.5 | 4.2 | 1.4 | 0.2 | setosa |
| 4.9 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.2 | 1.2 | 0.2 | setosa |
| 5.5 | 3.5 | 1.3 | 0.2 | setosa |
| 4.9 | 3.6 | 1.4 | 0.1 | setosa |
| 4.4 | 3.0 | 1.3 | 0.2 | setosa |
| 5.1 | 3.4 | 1.5 | 0.2 | setosa |
| 5.0 | 3.5 | 1.3 | 0.3 | setosa |
| 4.5 | 2.3 | 1.3 | 0.3 | setosa |
| 4.4 | 3.2 | 1.3 | 0.2 | setosa |
| 5.0 | 3.5 | 1.6 | 0.6 | setosa |
| 5.1 | 3.8 | 1.9 | 0.4 | setosa |
| 4.8 | 3.0 | 1.4 | 0.3 | setosa |
| 5.1 | 3.8 | 1.6 | 0.2 | setosa |
| 4.6 | 3.2 | 1.4 | 0.2 | setosa |
| 5.3 | 3.7 | 1.5 | 0.2 | setosa |
| 5.0 | 3.3 | 1.4 | 0.2 | setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| 5.5 | 2.3 | 4.0 | 1.3 | versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | versicolor |
| 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 6.3 | 3.3 | 4.7 | 1.6 | versicolor |
| 4.9 | 2.4 | 3.3 | 1.0 | versicolor |
| 6.6 | 2.9 | 4.6 | 1.3 | versicolor |
| 5.2 | 2.7 | 3.9 | 1.4 | versicolor |
| 5.0 | 2.0 | 3.5 | 1.0 | versicolor |
| 5.9 | 3.0 | 4.2 | 1.5 | versicolor |
| 6.0 | 2.2 | 4.0 | 1.0 | versicolor |
| 6.1 | 2.9 | 4.7 | 1.4 | versicolor |
| 5.6 | 2.9 | 3.6 | 1.3 | versicolor |
| 6.7 | 3.1 | 4.4 | 1.4 | versicolor |
| 5.6 | 3.0 | 4.5 | 1.5 | versicolor |
| 5.8 | 2.7 | 4.1 | 1.0 | versicolor |
| 6.2 | 2.2 | 4.5 | 1.5 | versicolor |
| 5.6 | 2.5 | 3.9 | 1.1 | versicolor |
| 5.9 | 3.2 | 4.8 | 1.8 | versicolor |
| 6.1 | 2.8 | 4.0 | 1.3 | versicolor |
| 6.3 | 2.5 | 4.9 | 1.5 | versicolor |
| 6.1 | 2.8 | 4.7 | 1.2 | versicolor |
| 6.4 | 2.9 | 4.3 | 1.3 | versicolor |
| 6.6 | 3.0 | 4.4 | 1.4 | versicolor |
| 6.8 | 2.8 | 4.8 | 1.4 | versicolor |
| 6.7 | 3.0 | 5.0 | 1.7 | versicolor |
| 6.0 | 2.9 | 4.5 | 1.5 | versicolor |
| 5.7 | 2.6 | 3.5 | 1.0 | versicolor |
| 5.5 | 2.4 | 3.8 | 1.1 | versicolor |
| 5.5 | 2.4 | 3.7 | 1.0 | versicolor |
| 5.8 | 2.7 | 3.9 | 1.2 | versicolor |
| 6.0 | 2.7 | 5.1 | 1.6 | versicolor |
| 5.4 | 3.0 | 4.5 | 1.5 | versicolor |
| 6.0 | 3.4 | 4.5 | 1.6 | versicolor |
| 6.7 | 3.1 | 4.7 | 1.5 | versicolor |
| 6.3 | 2.3 | 4.4 | 1.3 | versicolor |
| 5.6 | 3.0 | 4.1 | 1.3 | versicolor |
| 5.5 | 2.5 | 4.0 | 1.3 | versicolor |
| 5.5 | 2.6 | 4.4 | 1.2 | versicolor |
| 6.1 | 3.0 | 4.6 | 1.4 | versicolor |
| 5.8 | 2.6 | 4.0 | 1.2 | versicolor |
| 5.0 | 2.3 | 3.3 | 1.0 | versicolor |
| 5.6 | 2.7 | 4.2 | 1.3 | versicolor |
| 5.7 | 3.0 | 4.2 | 1.2 | versicolor |
| 5.7 | 2.9 | 4.2 | 1.3 | versicolor |
| 6.2 | 2.9 | 4.3 | 1.3 | versicolor |
| 5.1 | 2.5 | 3.0 | 1.1 | versicolor |
| 5.7 | 2.8 | 4.1 | 1.3 | versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 7.1 | 3.0 | 5.9 | 2.1 | virginica |
| 6.3 | 2.9 | 5.6 | 1.8 | virginica |
| 6.5 | 3.0 | 5.8 | 2.2 | virginica |
| 7.6 | 3.0 | 6.6 | 2.1 | virginica |
| 4.9 | 2.5 | 4.5 | 1.7 | virginica |
| 7.3 | 2.9 | 6.3 | 1.8 | virginica |
| 6.7 | 2.5 | 5.8 | 1.8 | virginica |
| 7.2 | 3.6 | 6.1 | 2.5 | virginica |
| 6.5 | 3.2 | 5.1 | 2.0 | virginica |
| 6.4 | 2.7 | 5.3 | 1.9 | virginica |
| 6.8 | 3.0 | 5.5 | 2.1 | virginica |
| 5.7 | 2.5 | 5.0 | 2.0 | virginica |
| 5.8 | 2.8 | 5.1 | 2.4 | virginica |
| 6.4 | 3.2 | 5.3 | 2.3 | virginica |
| 6.5 | 3.0 | 5.5 | 1.8 | virginica |
| 7.7 | 3.8 | 6.7 | 2.2 | virginica |
| 7.7 | 2.6 | 6.9 | 2.3 | virginica |
| 6.0 | 2.2 | 5.0 | 1.5 | virginica |
| 6.9 | 3.2 | 5.7 | 2.3 | virginica |
| 5.6 | 2.8 | 4.9 | 2.0 | virginica |
| 7.7 | 2.8 | 6.7 | 2.0 | virginica |
| 6.3 | 2.7 | 4.9 | 1.8 | virginica |
| 6.7 | 3.3 | 5.7 | 2.1 | virginica |
| 7.2 | 3.2 | 6.0 | 1.8 | virginica |
| 6.2 | 2.8 | 4.8 | 1.8 | virginica |
| 6.1 | 3.0 | 4.9 | 1.8 | virginica |
| 6.4 | 2.8 | 5.6 | 2.1 | virginica |
| 7.2 | 3.0 | 5.8 | 1.6 | virginica |
| 7.4 | 2.8 | 6.1 | 1.9 | virginica |
| 7.9 | 3.8 | 6.4 | 2.0 | virginica |
| 6.4 | 2.8 | 5.6 | 2.2 | virginica |
| 6.3 | 2.8 | 5.1 | 1.5 | virginica |
| 6.1 | 2.6 | 5.6 | 1.4 | virginica |
| 7.7 | 3.0 | 6.1 | 2.3 | virginica |
| 6.3 | 3.4 | 5.6 | 2.4 | virginica |
| 6.4 | 3.1 | 5.5 | 1.8 | virginica |
| 6.0 | 3.0 | 4.8 | 1.8 | virginica |
| 6.9 | 3.1 | 5.4 | 2.1 | virginica |
| 6.7 | 3.1 | 5.6 | 2.4 | virginica |
| 6.9 | 3.1 | 5.1 | 2.3 | virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 6.8 | 3.2 | 5.9 | 2.3 | virginica |
| 6.7 | 3.3 | 5.7 | 2.5 | virginica |
| 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 5.9 | 3.0 | 5.1 | 1.8 | virginica |
#examine grouped data
iris%>%
group_by(Species)%>%
summarise(count=n())
# A tibble: 3 x 2
Species count
<fct> <int>
1 setosa 50
2 versicolor 50
3 virginica 50# Get descriptive statistics
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
Another handy package
install.packages("psych")
psych::describe(iris)
vars n mean sd median trimmed mad min max range
Sepal.Length 1 150 5.84 0.83 5.80 5.81 1.04 4.3 7.9 3.6
Sepal.Width 2 150 3.06 0.44 3.00 3.04 0.44 2.0 4.4 2.4
Petal.Length 3 150 3.76 1.77 4.35 3.76 1.85 1.0 6.9 5.9
Petal.Width 4 150 1.20 0.76 1.30 1.18 1.04 0.1 2.5 2.4
Species* 5 150 2.00 0.82 2.00 2.00 1.48 1.0 3.0 2.0
skew kurtosis se
Sepal.Length 0.31 -0.61 0.07
Sepal.Width 0.31 0.14 0.04
Petal.Length -0.27 -1.42 0.14
Petal.Width -0.10 -1.36 0.06
Species* 0.00 -1.52 0.07# ?psych::describe
Look up what mad, se, skewness, and kurtosis is… 🕵️
As demonstrated by the output from the previous code cells, our test data matches our expectations (note that the full Iris data set is listed on Wikipedia). These data consist of three types, each with fifty instances, and every row has four measured features (i.e., attributes). The four primary features of the data are Sepal Length, Sepal Width, Petal Length, and Petal Width. In simple terms, petals are the showy, colorful part of the Iris flower, while the sepals provide protection and support for the petals.
In addition, our cursory exploration of the DataFrame indicated the data are clean. One simple way to verify this is that the count is the same for every feature, and the descriptive statistics (e.g., min, max, and mean) are all numerical. If we had missing or bad data in our DataFrame, these measures would generally indicate the problem. If there were missing data, we could drop any instance with missing data by using the na.omit method, or alternatively insert a value by using mutate . An alternative, and powerful, technique for handling missing data is known as imputing, where we apply machine learning1 to generate realistic values for any missing data. This approach will be demonstrated in a subsequent module.
At this point, we have loaded our data, and verified the data are clean. The next step is to visualize the relationships between the different features in our data.
Lets use another package 😆
install.packages("GGally")
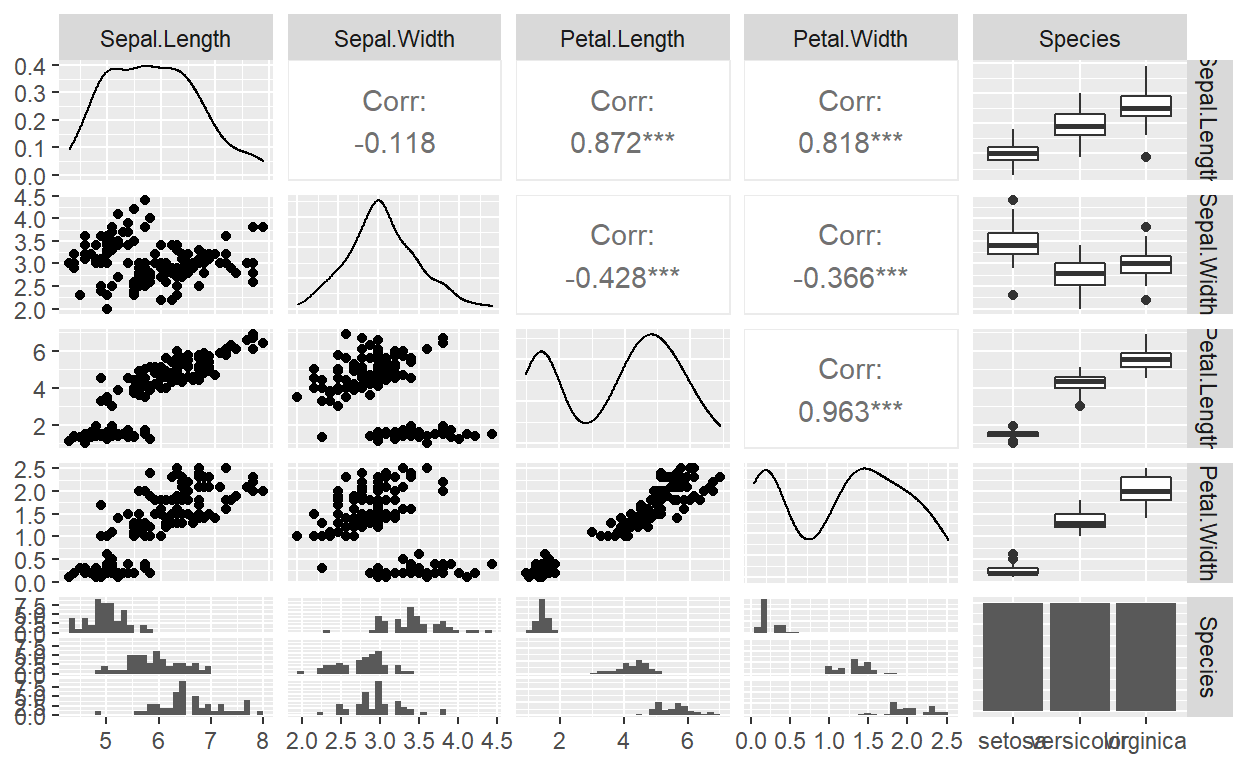
Look at me 👀 ggpairs function 👀
GGally::ggpairs(iris)
GGally::ggpairs(iris, aes(color = Species, alpha = 0.5))
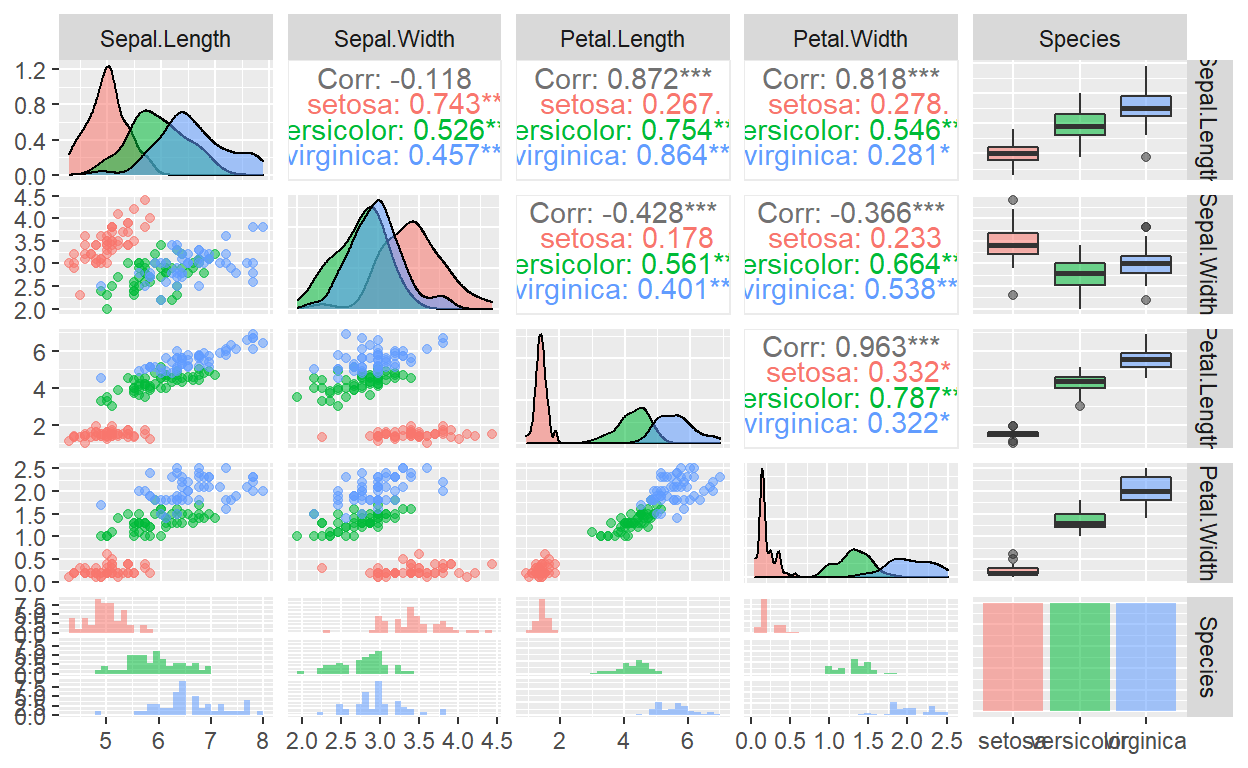
These figures indicate that the three Iris species cluster naturally in these dimensions, with minimal overlap. As a result, these data provide an excellent test for different machine learning algorithms.
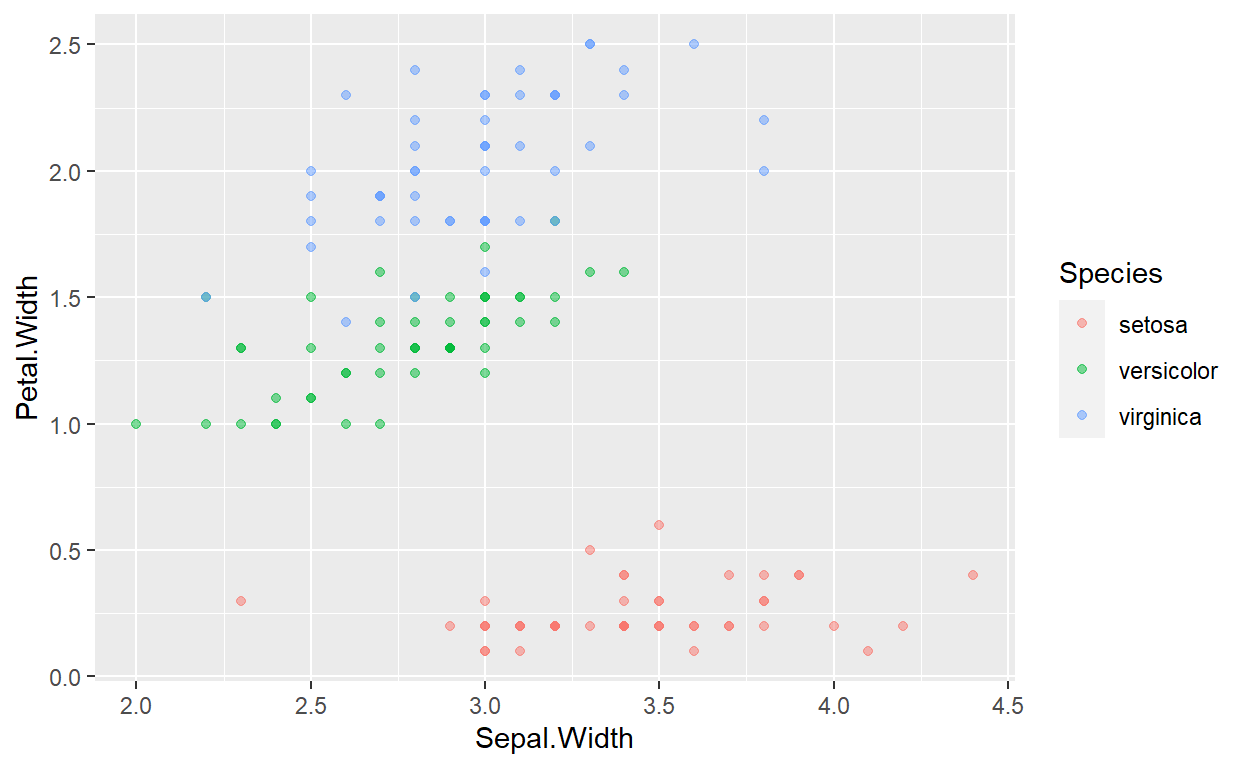
First, however, we will generate one scatter plot that displays a larger version of the Sepal Width versus Petal Width scatter plot to highlight the inherent structure in these data. Furthermore, we will refer back to this plot in later analyses in this Module.
#crash course in plots?
ggplot(data=iris,mapping = aes(x=Sepal.Width,y=Petal.Width,color=Species))+geom_point(alpha=0.5)
Side Note…Other plots 🙈
#line graph..this is a TERRIBLE example...
#ask me why
iris.setosa<-iris%>%
filter(Species=="setosa")%>%
distinct(Sepal.Width,.keep_all = TRUE)
ggplot(data=iris.setosa,mapping = aes(x=Sepal.Width,y=Sepal.Length))+geom_line()
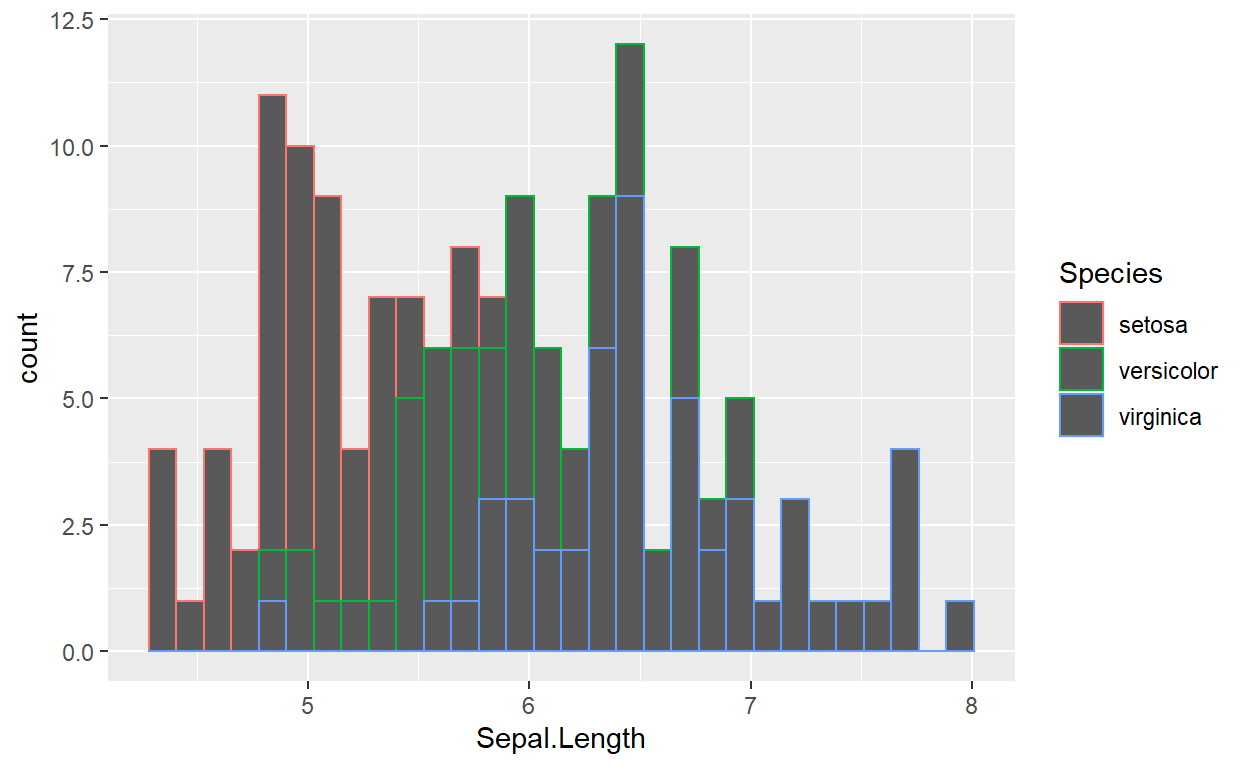
ggplot(data=iris,mapping = aes(x=Sepal.Length,color=Species))+geom_histogram()
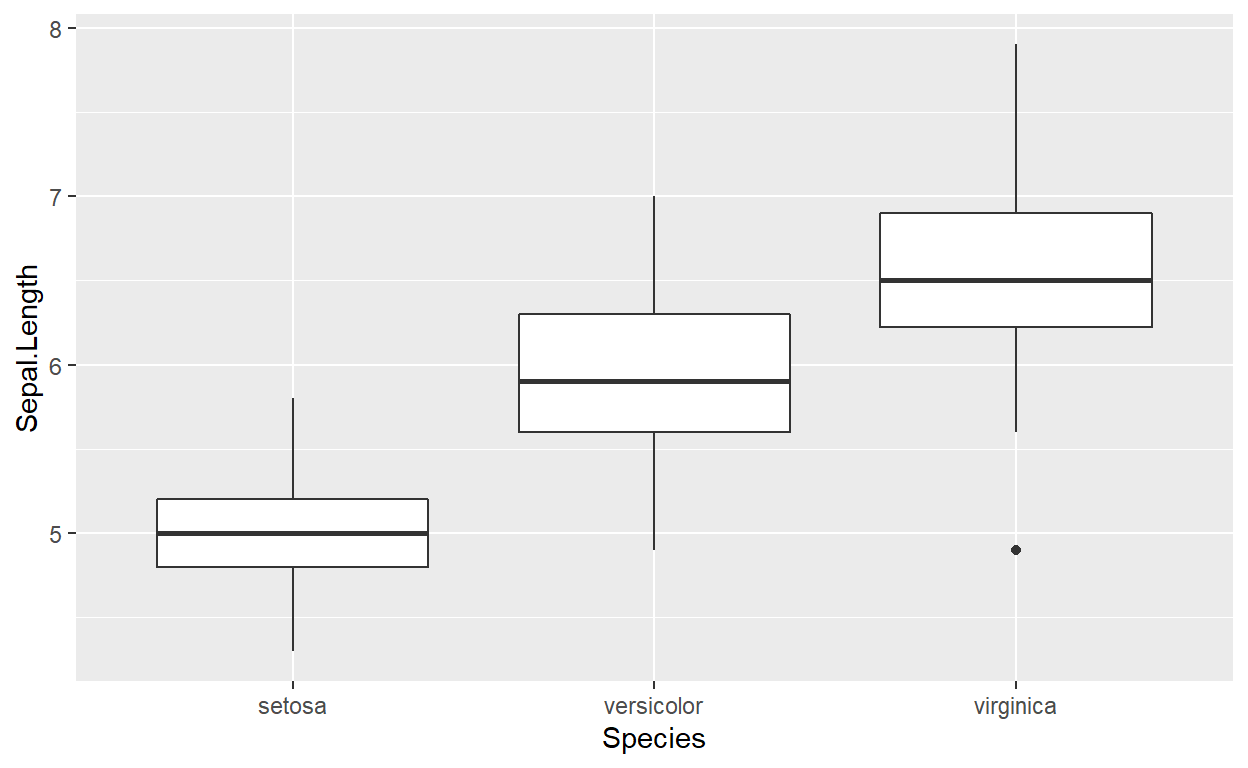
ggplot(data=iris,mapping = aes(x=Species,y=Sepal.Length))+geom_boxplot()
ggplot(data=iris,mapping = aes(x=Species))+geom_bar()

This is a narrow definition because you can also impute with summary statistics such as mean or median.↩︎