Bagging and Random Forest
In this module, we introduce the concept of bagging, which is shorthand for bootstrap aggregation, where random samples of the data are used to construct multiple decision trees. Since each tree only sees part of the data, each tree is less accurate than if it had been constructed over the full data set. Thus, each tree is known as a weak learner. A more powerful, meta-estimator is subsequently constructed by averaging over these many weak learners. The approach of constructing weak learners, and combining them into a more powerful estimator, is at the heart of several, very powerful machine learning techniques, including the random forest.
We first introduce the formalism behind bagging, including a discussion of the concept of bootstrapping. Next, we move on to a discussion of the random forest algorithm, which will include its application to both classification and regression tasks.
Formalism
One of the simplest machine learning algorithms to understand is the decision tree. Often, a decision tree is made as large as possible to provide the best predictive model, as this produces a high purity in the leaf nodes. Doing so, however, can lead to overfitting where the model predicts very accurately on the training data but fails to generalize to the test data; the accuracy is, as a result, much lower.
A simple approach to overcoming the overfitting problem is to train many decision trees on a subset of the data and to average the resulting predictions. This process is known as bootstrap aggregation, which is often shortened to bagging. Of these two terms, aggregation is simple to understand, one simply aggregates (or averages) the predictions of the many trees.
The term bootstrap is a statistical term that defines how a sample can be constructed from an original data set. Given a data set, there are two simple ways to construct a new sample. As a specific example, consider building a list of shows you wish to watch from an online provider like Netflix or Amazon by placing them in a virtual cart. In the first approach, you take a show of the virtual shelf and place it in your cart. This is known as sampling without replacement since the show is only present in your cart. In the second approach, you take a show and place it in your cart, but there remains a copy of the show on the virtual shelf. This is known as sampling with replacement, since we replace the original instance.
Sampling with replacement has several advantages that make it important for machine learning. First, we can construct many large samples from our original data set, where each sample is not limited by the size of the original data set. For example, if our original data set contained 100 entries, sampling without replacement would mean we could only create ten new samples that each had ten entries. On the other hand, sampling with replacement means we could create 100 (or more) new samples that each have ten (or more) entries.
Building many samples from a parent population allows us to build an estimator on each sample and average (or aggregate) the results. This is demonstrated in the following figure, where an original data set is used to train a number of decision trees. In this case, each tree is constructed from a bootstrap sample of the original data set. The predictions from these trees are aggregated at the end to make a final prediction.
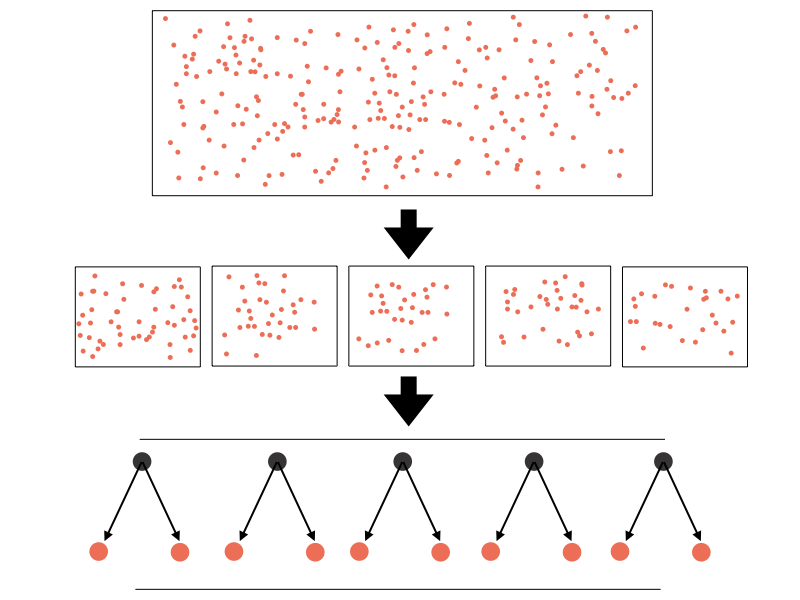
Beyond improved prediction, bagging algorithms provide an additional benefit. Since each tree (or other learning algorithm in the case of a Bagging estimator) is constructed from a subsample of the original data, the performance of that tree can be tested on the data from the original data that were not used in its construction. These data are known as out-of-bag data, and provide a useful metric for the performance of each individual tree used in the ensemble.
Before introducing the random forest, we first explore the construction and use of bootstrap samples.
Bootstrap
Formally, a bootstrap refers to any statistical process that relies on the generation of random samples with replacement. To demonstrate the benefit of the bootstrap, we will bootstrap the size feature from the tips data set, which is the number of patrons served by the restaurant for a meal.
Bootstrapping is a method that can be used to estimate the standard error of any statistic and produce a confidence interval for the statistic.
The basic process for bootstrapping is as follows:
- Take k repeated samples with replacement from a given dataset.
- For each sample, calculate the statistic you’re interested in.
- This results in k different estimates for a given statistic, which you can then use to calculate the standard error of the statistic and create a confidence interval for the statistic.
We can use the rsample package:
install.packages("rsample")
The initial power of the bootstrap results from our ability to extend the creation of this one sample to many.
library(curl)
load(curl("https://raw.githubusercontent.com/Professor-Hunt/ACC8143/main/data/tips.rda"))
set.seed(0)
library(rsample)
library(tidyverse)
#perform bootstrapping with 2000 replications
resample1 <- bootstraps(as.data.frame(tips$size), times = 100)
#view results of boostrapping
knitr::kable(head(summary(resample1),5))
| splits.Length splits.Class splits.Mode | id | |
|---|---|---|
| 4 boot_split list | Length:100 | |
| 4 boot_split list | Class :character | |
| 4 boot_split list | Mode :character | |
| 4 boot_split list | NA | |
| 4 boot_split list | NA |
#info for a specific sample
resample1$splits[[1]]
<Analysis/Assess/Total>
<244/91/244>#mean
mean(resample1$splits[[1]]$data$`tips$size`)
[1] 2.569672#standard deviation
sd(resample1$splits[[1]]$data$`tips$size`)
[1] 0.9510998Of course, we do not need to compute these statistics across the entire sample, we can compute the mean for each sample, creating an array of means. In this case, we can consider each sample mean to be an estimate of the mean of the parent population. We can average these means (i.e., aggregate) these sample means to provide an estimate of the population mean, along with a measure of the uncertainty in this estimate, by computing the standard deviation of our sample means.
#get all of them
mean_values<-purrr::map_dbl(resample1$splits,
function(x) {
dat <- as.data.frame(x)$`tips$size`
mean(dat)
})
#view the whole dataset
knitr::kable(mean_values)%>%
kableExtra::kable_styling("striped")%>%
kableExtra::scroll_box(width = "50%",height="300px")
| x |
|---|
| 2.553279 |
| 2.536885 |
| 2.524590 |
| 2.495902 |
| 2.512295 |
| 2.692623 |
| 2.520492 |
| 2.565574 |
| 2.491803 |
| 2.565574 |
| 2.635246 |
| 2.581967 |
| 2.581967 |
| 2.532787 |
| 2.512295 |
| 2.565574 |
| 2.627049 |
| 2.647541 |
| 2.565574 |
| 2.553279 |
| 2.545082 |
| 2.532787 |
| 2.500000 |
| 2.545082 |
| 2.540984 |
| 2.532787 |
| 2.524590 |
| 2.565574 |
| 2.573771 |
| 2.545082 |
| 2.581967 |
| 2.536885 |
| 2.561475 |
| 2.520492 |
| 2.577869 |
| 2.635246 |
| 2.549180 |
| 2.631147 |
| 2.569672 |
| 2.504098 |
| 2.532787 |
| 2.610656 |
| 2.540984 |
| 2.590164 |
| 2.606557 |
| 2.471312 |
| 2.602459 |
| 2.622951 |
| 2.512295 |
| 2.516393 |
| 2.577869 |
| 2.655738 |
| 2.553279 |
| 2.528688 |
| 2.586066 |
| 2.668033 |
| 2.622951 |
| 2.590164 |
| 2.725410 |
| 2.709016 |
| 2.520492 |
| 2.594262 |
| 2.581967 |
| 2.536885 |
| 2.590164 |
| 2.573771 |
| 2.536885 |
| 2.569672 |
| 2.717213 |
| 2.450820 |
| 2.434426 |
| 2.540984 |
| 2.540984 |
| 2.565574 |
| 2.696721 |
| 2.475410 |
| 2.577869 |
| 2.627049 |
| 2.577869 |
| 2.520492 |
| 2.639344 |
| 2.668033 |
| 2.540984 |
| 2.471312 |
| 2.606557 |
| 2.618853 |
| 2.573771 |
| 2.553279 |
| 2.663934 |
| 2.553279 |
| 2.610656 |
| 2.569672 |
| 2.540984 |
| 2.606557 |
| 2.487705 |
| 2.606557 |
| 2.545082 |
| 2.524590 |
| 2.553279 |
| 2.524590 |
#estimate of the population mean
mean(mean_values)
[1] 2.568484#get all of them
sd_values<-purrr::map_dbl(resample1$splits,
function(x) {
dat <- as.data.frame(x)$`tips$size`
sd(dat)
})
#view the whole dataset
knitr::kable(sd_values)%>%
kableExtra::kable_styling("striped")%>%
kableExtra::scroll_box(width = "50%",height="300px")
| x |
|---|
| 0.9391077 |
| 0.9041924 |
| 0.9000513 |
| 0.8725251 |
| 0.9664391 |
| 1.0500769 |
| 0.9662995 |
| 0.9250755 |
| 0.9049103 |
| 0.9978389 |
| 0.9396105 |
| 1.0331156 |
| 0.9672851 |
| 0.9616894 |
| 0.9361578 |
| 0.9025588 |
| 0.9319687 |
| 1.0297799 |
| 1.0382615 |
| 0.9214128 |
| 1.0433093 |
| 0.8671834 |
| 0.9184886 |
| 0.8946666 |
| 0.8856194 |
| 0.9994602 |
| 0.9226292 |
| 0.9161352 |
| 0.9288963 |
| 0.8713645 |
| 1.0048456 |
| 0.9615403 |
| 0.9981008 |
| 0.9956646 |
| 1.0051728 |
| 0.9782341 |
| 0.9216416 |
| 0.9401937 |
| 1.0458926 |
| 0.8725251 |
| 0.9179009 |
| 0.9072463 |
| 0.8809604 |
| 0.9876113 |
| 0.9476623 |
| 0.8529763 |
| 0.9695753 |
| 1.0369937 |
| 0.8436720 |
| 0.9915993 |
| 0.8970012 |
| 1.0405008 |
| 0.9214128 |
| 0.8673292 |
| 0.9796124 |
| 1.0543085 |
| 0.9671805 |
| 0.9362749 |
| 1.0669029 |
| 1.1080331 |
| 0.9403999 |
| 0.9830497 |
| 0.9924834 |
| 0.8622586 |
| 0.9665526 |
| 0.9420932 |
| 0.8950436 |
| 0.9809200 |
| 1.1644383 |
| 0.8423215 |
| 0.8887750 |
| 0.9825434 |
| 0.9130741 |
| 0.9295134 |
| 1.0052483 |
| 0.8954675 |
| 0.9633628 |
| 1.0364975 |
| 0.9590815 |
| 0.8816780 |
| 0.9477335 |
| 0.9981684 |
| 0.8620727 |
| 0.8673292 |
| 0.8940349 |
| 1.0093254 |
| 0.9244554 |
| 0.9169357 |
| 0.9653303 |
| 0.8988044 |
| 0.9686703 |
| 0.9682524 |
| 1.0032666 |
| 1.0107030 |
| 0.8771519 |
| 0.9733687 |
| 0.9307373 |
| 0.9576473 |
| 0.9303023 |
| 0.8815728 |
#estimate of the population standard deviation
sd(sd_values)
[1] 0.06087578This simple example has demonstrated how bootstrap aggregation, in this case of the sample means, can provide a powerful estimator of a population statistic. In each case, we generate multiple samples with replacement, compute statistics across these samples, and aggregate the result at the end. This concept underlies all bagging estimators.
Exercise 1
- Redo the bootstrap analysis, but use 10 samples. Change
times = 100totimes = 10. How does the population estimate for mean change? - Redo the bootstrap analysis, but find the median. What is the difference in population estimate for the median vs mean?
Random Forest
A random forest employs bagging to create a set of decision trees from a given data set. Each tree is constructed from a bootstrap sample, and the final prediction is generated by aggregating the predictions of the individual trees, just like the previous code example demonstrated by using the mean of the sample means to estimate the mean of the parent population. However, the random forest introduces one additional random concept into the tree construction.
Normally, when deciding on a split point during the construction of a decision tree, all features are evaluated and the one that has the highest impurity (or produces the largest information gain) is selected as the feature on which to split, along with the value at which to split that feature. In a random forest, a random subset of all features is used to make the split choice, and the best feature on which to split is selected form this subset.
This extra randomness produces individual decision trees that are less sensitive to small-scale fluctuations, which is known as under-fitting. As a result, each newly created decision tree is a weak learner since they are not constructed from all available information. Yet, since each decision tree is constructed from different sets of features, by aggregating their predictions, the final random forest prediction is improved and less affected by overfitting.
Each tree in the random forest is constructed from a different combination of features. As a result, we can use the out-of-bag performance from each tree to rank the importance of the features used to construct the trees in the forest. This allows for robust estimates of feature importance to be computed after constructing a random forest, which can provide useful insight into the nature of a training data set.
Random Forest: Classification
Having completed the discussion on bootstrap aggregation, and introduced the random forest algorithm, we can now transition to putting this powerful ensemble algorithm to work.
set.seed(1)
#lets split the data 60/40
library(caret)
trainIndex <- createDataPartition(iris$Species, p = .6, list = FALSE, times = 1)
#grab the data
irisTrain <- iris[ trainIndex,]
irisTest <- iris[-trainIndex,]
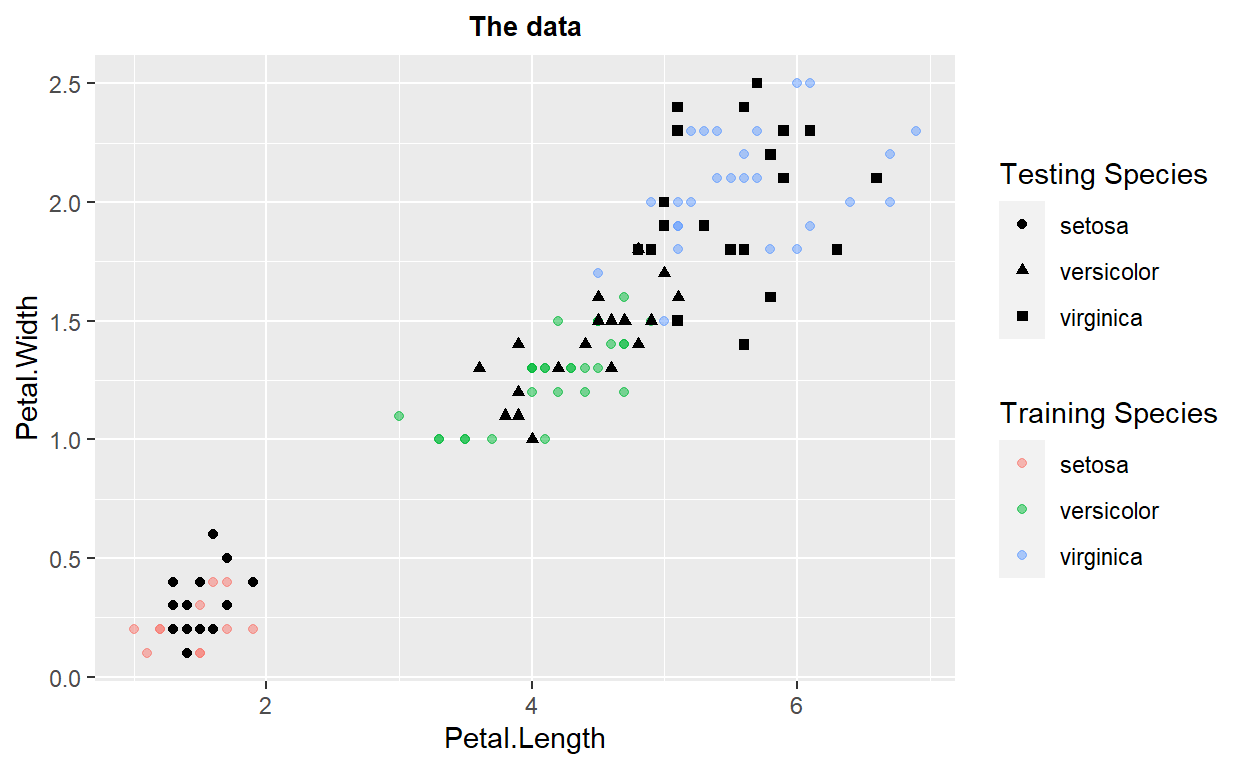
ggplot(data=irisTrain)+geom_point(mapping = aes(x=Petal.Length,y=Petal.Width,color=Species),alpha=0.5) + labs(color = "Training Species")+
geom_point(data=irisTest, ,mapping = aes(x=Petal.Length,y=Petal.Width,shape=Species)) + labs(shape = "Testing Species") +
ggtitle("The data")+
theme(plot.title = element_text(hjust=0.5, size=10, face='bold'))
The model
set.seed(1)
IrisRF<- train(
form = factor(Species) ~ .,
data = irisTrain,
#here we add classProbs because we want probs
trControl = trainControl(method = "cv", number = 10,
classProbs = TRUE),
method = "rf",
tuneLength = 3)#why 3?
IrisRF
Random Forest
90 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 81, 81, 81, 81, 81, 81, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9666667 0.95
3 0.9666667 0.95
4 0.9666667 0.95
Accuracy was used to select the optimal model using the
largest value.
The final value used for the model was mtry = 2.summary(IrisRF)
Length Class Mode
call 4 -none- call
type 1 -none- character
predicted 90 factor numeric
err.rate 2000 -none- numeric
confusion 12 -none- numeric
votes 270 matrix numeric
oob.times 90 -none- numeric
classes 3 -none- character
importance 4 -none- numeric
importanceSD 0 -none- NULL
localImportance 0 -none- NULL
proximity 0 -none- NULL
ntree 1 -none- numeric
mtry 1 -none- numeric
forest 14 -none- list
y 90 factor numeric
test 0 -none- NULL
inbag 0 -none- NULL
xNames 4 -none- character
problemType 1 -none- character
tuneValue 1 data.frame list
obsLevels 3 -none- character
param 0 -none- list IrisRF_Pred<-predict(IrisRF,irisTest,type="prob")
knitr::kable(IrisRF_Pred)%>%
kableExtra::kable_styling("striped")%>%
kableExtra::scroll_box(width = "50%",height="300px")
| setosa | versicolor | virginica | |
|---|---|---|---|
| 2 | 0.996 | 0.004 | 0.000 |
| 5 | 1.000 | 0.000 | 0.000 |
| 8 | 1.000 | 0.000 | 0.000 |
| 11 | 0.998 | 0.002 | 0.000 |
| 13 | 0.996 | 0.004 | 0.000 |
| 16 | 0.964 | 0.036 | 0.000 |
| 17 | 0.998 | 0.002 | 0.000 |
| 19 | 0.964 | 0.036 | 0.000 |
| 24 | 1.000 | 0.000 | 0.000 |
| 28 | 1.000 | 0.000 | 0.000 |
| 30 | 1.000 | 0.000 | 0.000 |
| 32 | 0.994 | 0.006 | 0.000 |
| 35 | 1.000 | 0.000 | 0.000 |
| 37 | 0.940 | 0.060 | 0.000 |
| 38 | 1.000 | 0.000 | 0.000 |
| 42 | 0.946 | 0.050 | 0.004 |
| 44 | 1.000 | 0.000 | 0.000 |
| 45 | 1.000 | 0.000 | 0.000 |
| 46 | 0.996 | 0.004 | 0.000 |
| 50 | 1.000 | 0.000 | 0.000 |
| 53 | 0.000 | 0.686 | 0.314 |
| 55 | 0.000 | 0.956 | 0.044 |
| 59 | 0.000 | 0.956 | 0.044 |
| 60 | 0.006 | 0.982 | 0.012 |
| 63 | 0.000 | 0.942 | 0.058 |
| 65 | 0.000 | 1.000 | 0.000 |
| 66 | 0.002 | 0.954 | 0.044 |
| 70 | 0.000 | 0.998 | 0.002 |
| 71 | 0.004 | 0.112 | 0.884 |
| 76 | 0.000 | 0.956 | 0.044 |
| 77 | 0.000 | 0.814 | 0.186 |
| 78 | 0.000 | 0.114 | 0.886 |
| 81 | 0.000 | 1.000 | 0.000 |
| 83 | 0.000 | 1.000 | 0.000 |
| 84 | 0.000 | 0.448 | 0.552 |
| 85 | 0.058 | 0.894 | 0.048 |
| 86 | 0.014 | 0.968 | 0.018 |
| 87 | 0.002 | 0.950 | 0.048 |
| 95 | 0.000 | 1.000 | 0.000 |
| 97 | 0.000 | 1.000 | 0.000 |
| 103 | 0.000 | 0.002 | 0.998 |
| 104 | 0.000 | 0.010 | 0.990 |
| 105 | 0.000 | 0.000 | 1.000 |
| 106 | 0.000 | 0.000 | 1.000 |
| 108 | 0.000 | 0.000 | 1.000 |
| 112 | 0.000 | 0.000 | 1.000 |
| 114 | 0.000 | 0.034 | 0.966 |
| 115 | 0.000 | 0.000 | 1.000 |
| 124 | 0.000 | 0.056 | 0.944 |
| 127 | 0.000 | 0.132 | 0.868 |
| 130 | 0.000 | 0.446 | 0.554 |
| 134 | 0.000 | 0.480 | 0.520 |
| 135 | 0.000 | 0.496 | 0.504 |
| 136 | 0.000 | 0.000 | 1.000 |
| 137 | 0.000 | 0.004 | 0.996 |
| 138 | 0.000 | 0.008 | 0.992 |
| 142 | 0.000 | 0.002 | 0.998 |
| 144 | 0.000 | 0.002 | 0.998 |
| 145 | 0.000 | 0.002 | 0.998 |
| 147 | 0.000 | 0.048 | 0.952 |
irisrftestpred<-cbind(IrisRF_Pred,irisTest)
irisrftestpred<-irisrftestpred%>%
mutate(prediction=if_else(setosa>versicolor & setosa>virginica,"setosa",
if_else(versicolor>setosa & versicolor>virginica, "versicolor",
if_else(virginica>setosa & virginica>versicolor,"virginica", "PROBLEM"))))
table(irisrftestpred$prediction)
setosa versicolor virginica
20 17 23 confusionMatrix(factor(irisrftestpred$prediction),factor(irisrftestpred$Species))
Confusion Matrix and Statistics
Reference
Prediction setosa versicolor virginica
setosa 20 0 0
versicolor 0 17 0
virginica 0 3 20
Overall Statistics
Accuracy : 0.95
95% CI : (0.8608, 0.9896)
No Information Rate : 0.3333
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.925
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: setosa Class: versicolor Class: virginica
Sensitivity 1.0000 0.8500 1.0000
Specificity 1.0000 1.0000 0.9250
Pos Pred Value 1.0000 1.0000 0.8696
Neg Pred Value 1.0000 0.9302 1.0000
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.2833 0.3333
Detection Prevalence 0.3333 0.2833 0.3833
Balanced Accuracy 1.0000 0.9250 0.9625Random Forest: Feature Importance
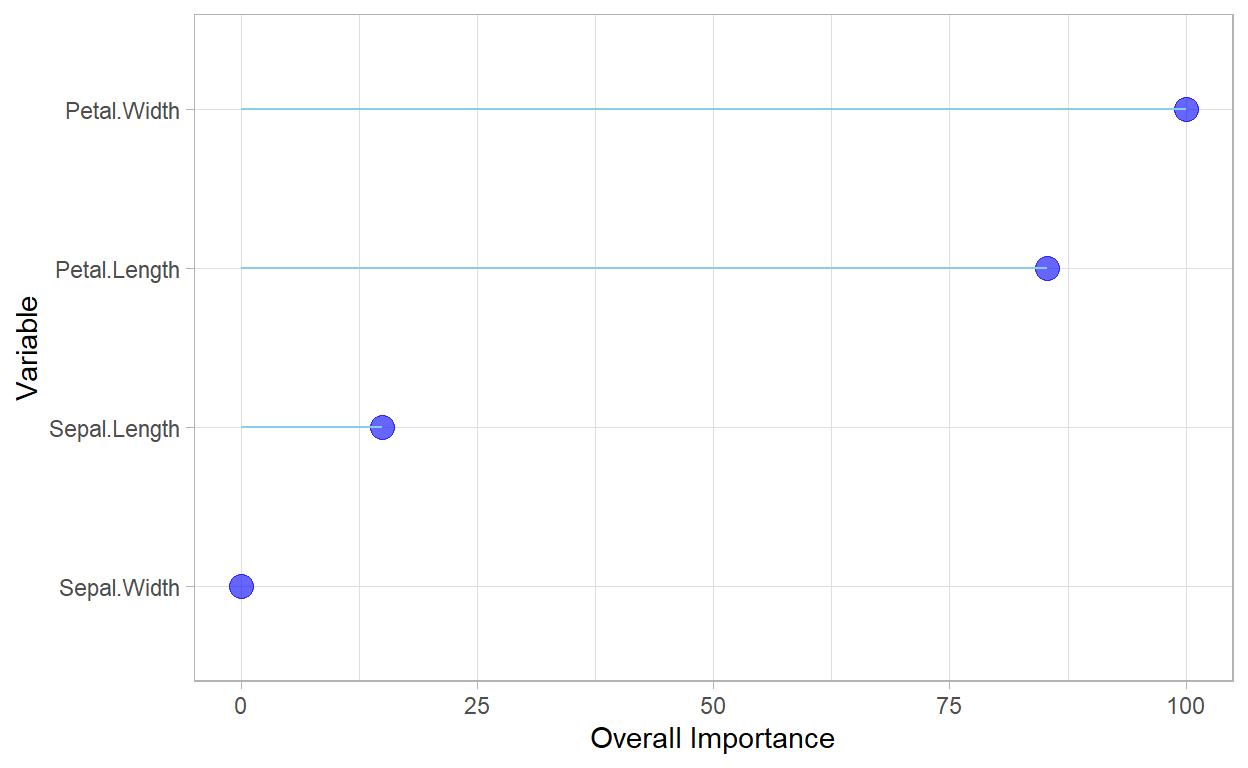
As the previous example demonstrated, the random forest is easy to use and often provides impressive results. In addition, by its very nature, a random forest provides an implicit measure of the importance of the individual features in generating the final predictions. While an individual decision tree provides this information, the random forest provides an aggregated result that is generally more insightful and less sensitive to fluctuations in the training data that might bias the importance values determined by a decision tree. In the calculation of feature importance from a random forest, higher values indicate a more important feature.
| Overall | |
|---|---|
| Petal.Width | 100.00000 |
| Petal.Length | 85.27446 |
| Sepal.Length | 14.94842 |
| Sepal.Width | 0.00000 |
ggplot2::ggplot(V, aes(x=reorder(rownames(V),Overall), y=Overall)) +
geom_point( color="blue", size=4, alpha=0.6)+
geom_segment( aes(x=rownames(V), xend=rownames(V), y=0, yend=Overall),
color='skyblue') +
xlab('Variable')+
ylab('Overall Importance')+
theme_light() +
coord_flip()
Exercise 2
- Use the tips data and predict
sex. Use only continuous variables. What are the results? - Use the tips data and predict
sex. Use all of the variables. Did the model improve from 1? - What are the most important variables from 2?
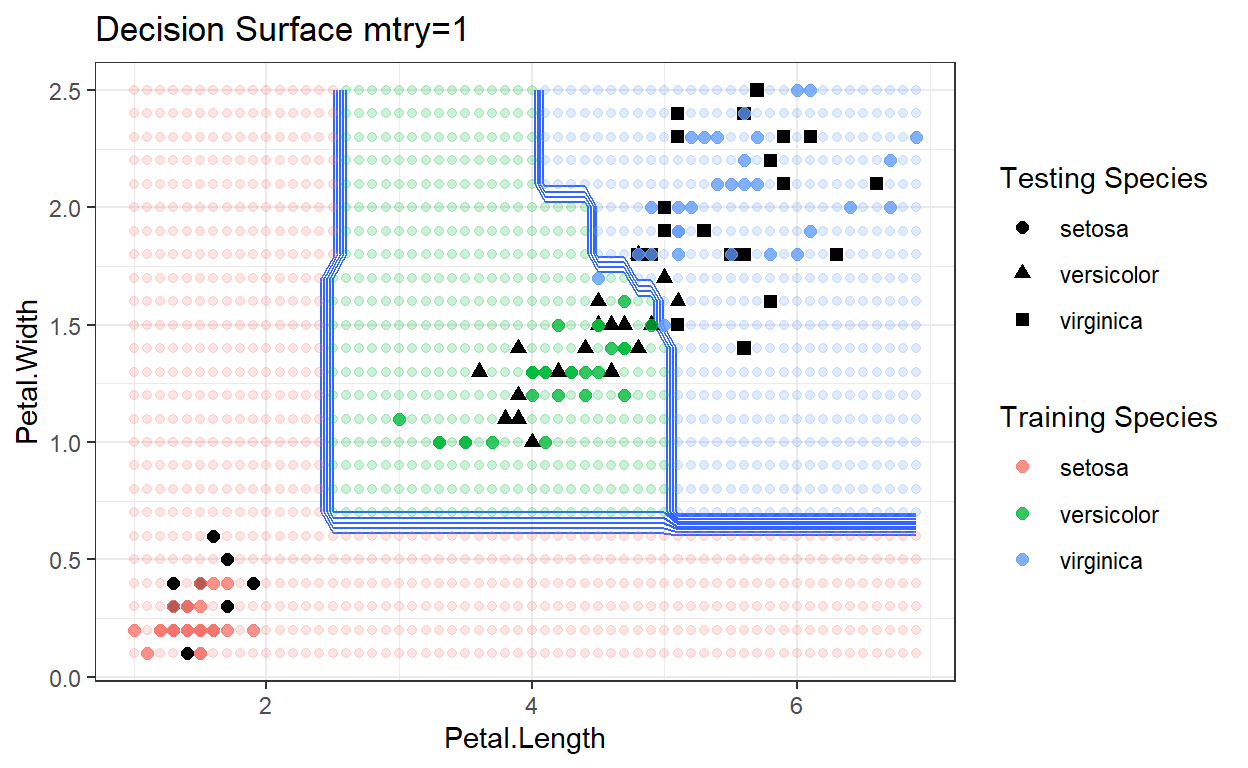
Decision Surfaces
set.seed(1)
#lets split the data 60/40
library(caret)
trainIndex <- createDataPartition(iris$Species, p = .6, list = FALSE, times = 1)
#grab the data
train <- iris[ trainIndex,]
test <- iris[-trainIndex,]
IrisRF<- train(
form = factor(Species) ~ .,
data = train,
#here we add classProbs because we want probs
trControl = trainControl(method = "cv", number = 10,
classProbs = TRUE),
method = "rf",
tuneGrid=data.frame(mtry=1))
pl = seq(min(iris$Petal.Length), max(iris$Petal.Length), by=0.1)
pw = seq(min(iris$Petal.Width), max(iris$Petal.Width), by=0.1)
# generates the boundaries for your graph
lgrid <- expand.grid(Petal.Length=pl,
Petal.Width=pw,
Sepal.Length = 5.4,
Sepal.Width=3.1)
IrisRFGrid2 <- predict(IrisRF, newdata=lgrid)
IrisRFGrid <- as.numeric(IrisRFGrid2)
# get the points from the test data...
testPred <- predict(IrisRF, newdata=test)
testPred <- as.numeric(testPred)
# this gets the points for the testPred...
test$Pred <- testPred
probs <- matrix(IrisRFGrid, length(pl), length(pw))
ggplot(data=lgrid) + stat_contour(aes(x=Petal.Length, y=Petal.Width, z=IrisRFGrid),bins=10) +
geom_point(aes(x=Petal.Length, y=Petal.Width, colour=IrisRFGrid2),alpha=.2) +
geom_point(data=test, aes(x=Petal.Length, y=Petal.Width, shape=Species), size=2) +
labs(shape = "Testing Species") +
geom_point(data=train, aes(x=Petal.Length, y=Petal.Width, color=Species), size=2, alpha=0.75)+
theme_bw()+
labs(color = "Training Species")+
ggtitle("Decision Surface mtry=1")
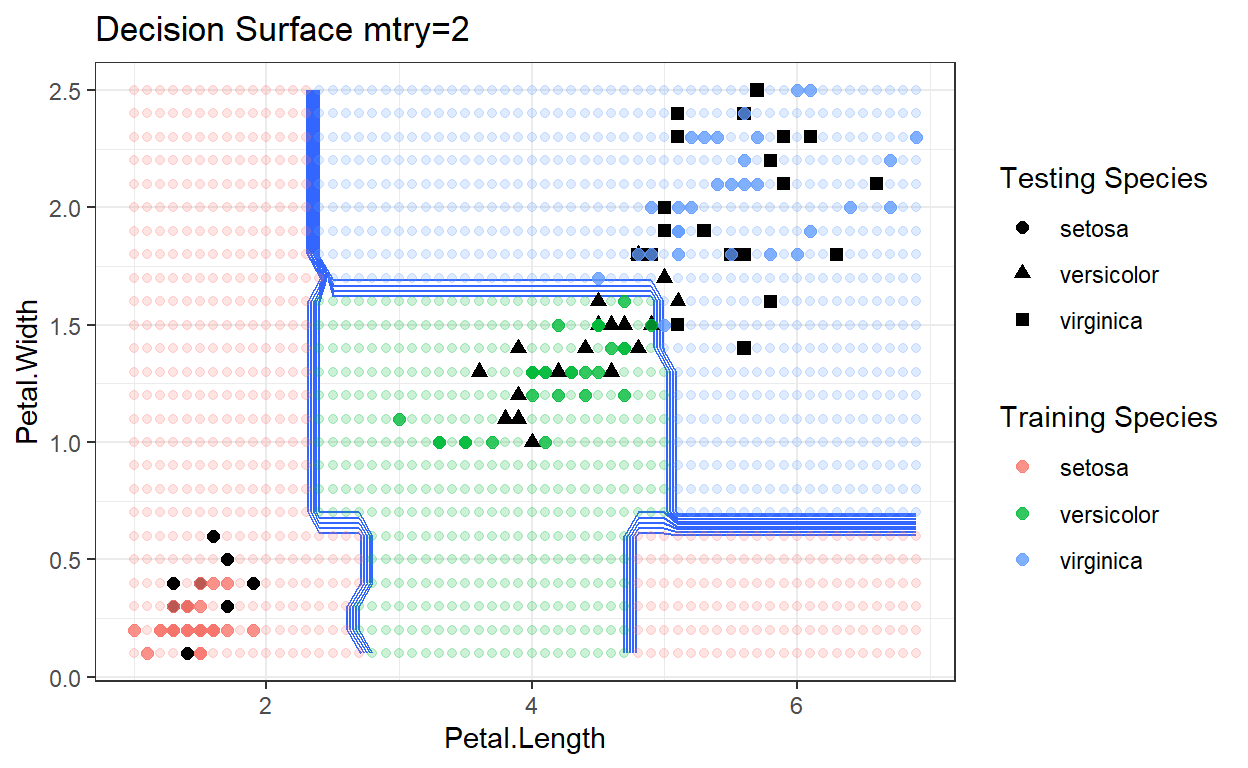
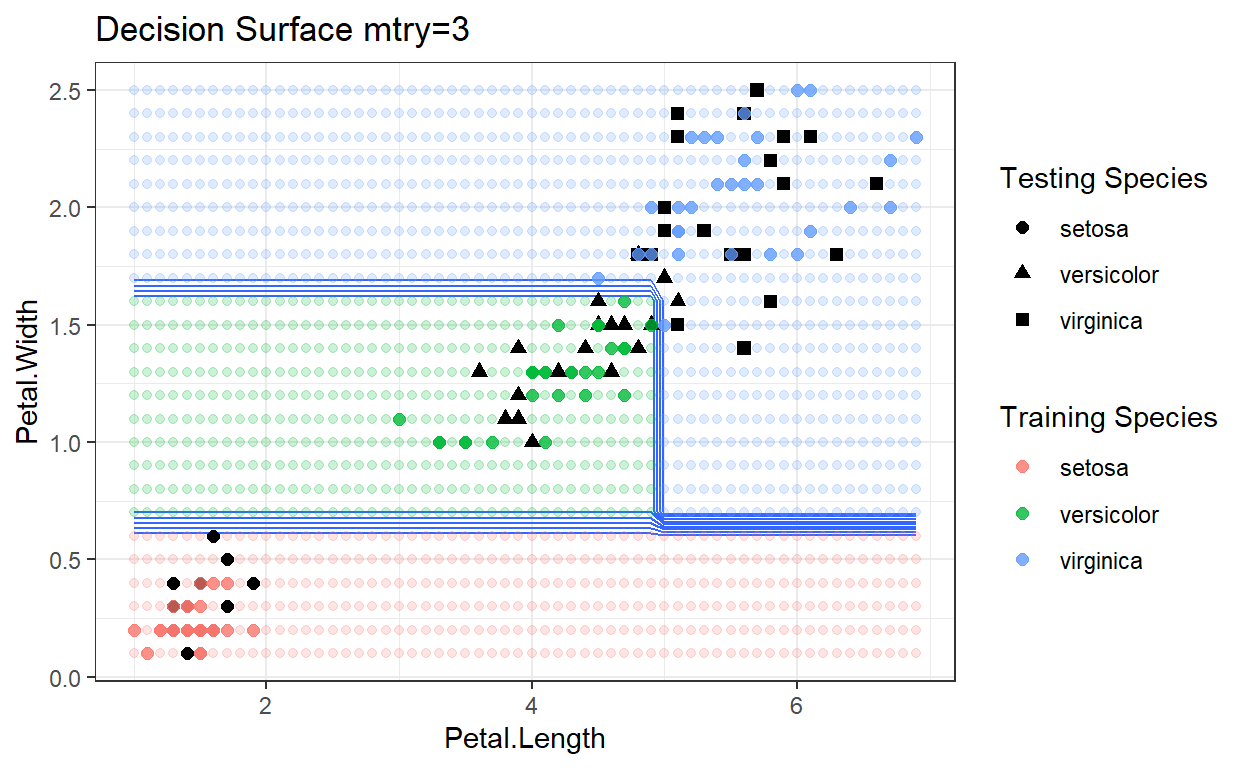
Random Forrest: Regression
A random forest can also be used to perform regression; however, in this case the goal is to create trees whose leaf nodes contain data that are nearby in the overall feature space. To predict a continuous value from a tree we either have leaf nodes with only one feature, and use the relevant feature from that instance as our predictor, or we compute summary statistics from the instances in the appropriate leaf node, such as the mean or mode. In the end, the random forest aggregates the individual tree regression predictions into a final prediction.
set.seed(1)
IrisRF<- train(
form = Sepal.Width ~ .,
data = irisTrain,
#here we add classProbs because we want probs
trControl = trainControl(method = "cv", number = 10),
method = "rf",
tuneLength = 3)#why 3?
IrisRF
Random Forest
90 samples
4 predictor
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 81, 81, 80, 80, 81, 81, ...
Resampling results across tuning parameters:
mtry RMSE Rsquared MAE
2 0.3143813 0.5629816 0.2465506
3 0.3151144 0.5667041 0.2440860
5 0.3250253 0.5507325 0.2510316
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was mtry = 2.summary(IrisRF)
Length Class Mode
call 4 -none- call
type 1 -none- character
predicted 90 -none- numeric
mse 500 -none- numeric
rsq 500 -none- numeric
oob.times 90 -none- numeric
importance 5 -none- numeric
importanceSD 0 -none- NULL
localImportance 0 -none- NULL
proximity 0 -none- NULL
ntree 1 -none- numeric
mtry 1 -none- numeric
forest 11 -none- list
coefs 0 -none- NULL
y 90 -none- numeric
test 0 -none- NULL
inbag 0 -none- NULL
xNames 5 -none- character
problemType 1 -none- character
tuneValue 1 data.frame list
obsLevels 1 -none- logical
param 0 -none- list IrisRF_Pred<-predict(IrisRF,irisTest)
knitr::kable(IrisRF_Pred)%>%
kableExtra::kable_styling("striped")%>%
kableExtra::scroll_box(width = "50%",height="300px")
| x | |
|---|---|
| 2 | 3.260807 |
| 5 | 3.277757 |
| 8 | 3.276376 |
| 11 | 3.625285 |
| 13 | 3.292194 |
| 16 | 3.780434 |
| 17 | 3.618677 |
| 19 | 3.727191 |
| 24 | 3.635188 |
| 28 | 3.591418 |
| 30 | 3.261777 |
| 32 | 3.696874 |
| 35 | 3.253701 |
| 37 | 3.701131 |
| 38 | 3.291458 |
| 42 | 3.302038 |
| 44 | 3.441303 |
| 45 | 3.635421 |
| 46 | 3.385235 |
| 50 | 3.277757 |
| 53 | 2.909713 |
| 55 | 2.974078 |
| 59 | 2.889188 |
| 60 | 2.528744 |
| 63 | 2.622728 |
| 65 | 2.617352 |
| 66 | 2.897548 |
| 70 | 2.601872 |
| 71 | 2.980619 |
| 76 | 2.887018 |
| 77 | 3.027017 |
| 78 | 2.965986 |
| 81 | 2.457501 |
| 83 | 2.670909 |
| 84 | 2.845308 |
| 85 | 2.657226 |
| 86 | 2.918538 |
| 87 | 3.007142 |
| 95 | 2.857735 |
| 97 | 2.864092 |
| 103 | 3.094478 |
| 104 | 2.919063 |
| 105 | 3.038040 |
| 106 | 3.145111 |
| 108 | 3.058734 |
| 112 | 2.931478 |
| 114 | 2.810783 |
| 115 | 2.952067 |
| 124 | 2.919760 |
| 127 | 2.924434 |
| 130 | 2.848639 |
| 134 | 2.699231 |
| 135 | 2.728545 |
| 136 | 3.257096 |
| 137 | 3.127867 |
| 138 | 2.942718 |
| 142 | 3.114100 |
| 144 | 3.106644 |
| 145 | 3.227185 |
| 147 | 2.875940 |
irisrftestpred<-cbind(IrisRF_Pred,irisTest)
#root mean squared error
RMSE(irisrftestpred$IrisRF_Pred,irisrftestpred$Sepal.Width)
[1] 0.254781#best measure ever...RSquared
cor(irisrftestpred$IrisRF_Pred,irisrftestpred$Sepal.Width)^2
[1] 0.6169456Exercise 3
- Rerun the regression analysis, but change
form = Sepal.Width ~ .,toform = Sepal.Width ~ Sepal.Length+Petal.Length+Petal.Width+factor(Species),. Does anything change? Why?
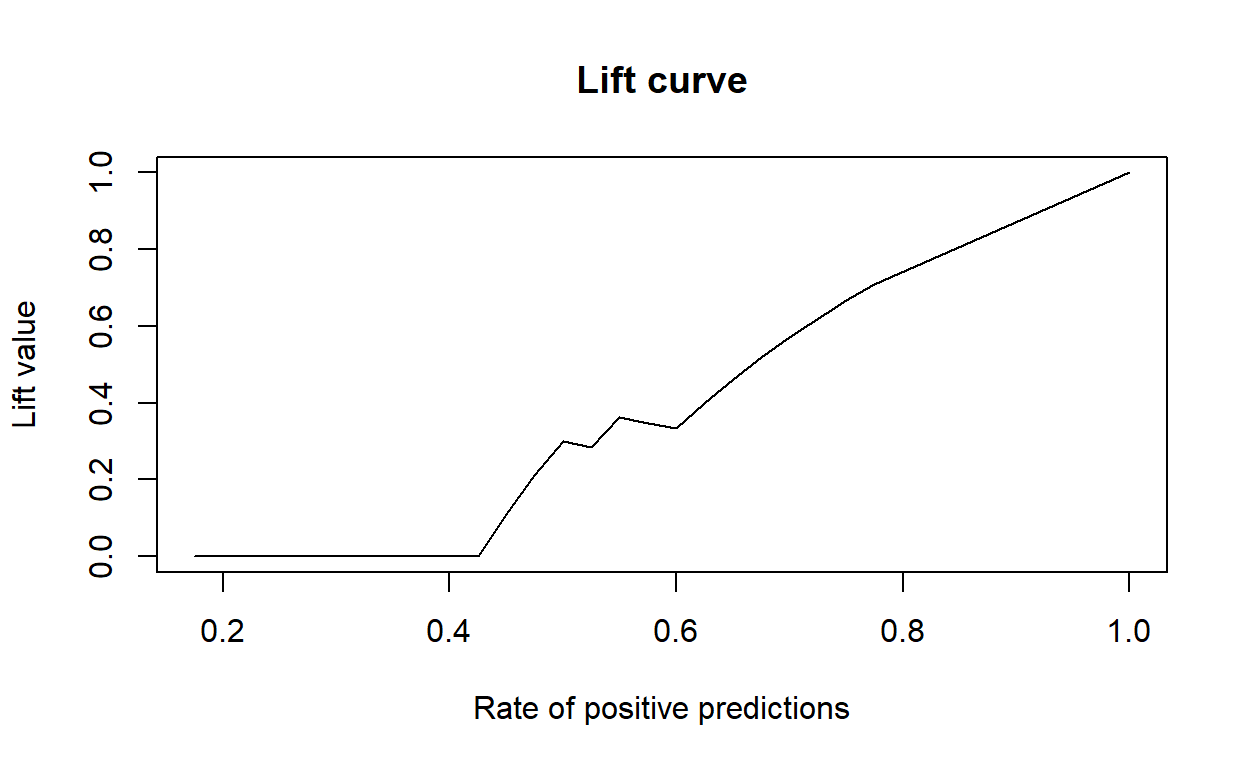
ROC, Gain, Lift
iristrain_2levels<-irisTrain%>%
filter(Species!="setosa")
set.seed(1)
IrisRF<- train(
form = factor(Species) ~ .,
data = iristrain_2levels,
#here we add classProbs because we want probs
trControl = trainControl(method = "cv", number = 10,
classProbs = TRUE),
method = "rf",
tuneLength = 3)#why 3?
IrisRF
Random Forest
60 samples
4 predictor
2 classes: 'versicolor', 'virginica'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 54, 54, 54, 54, 54, 54, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.95 0.9
3 0.95 0.9
4 0.95 0.9
Accuracy was used to select the optimal model using the
largest value.
The final value used for the model was mtry = 2.summary(IrisRF)
Length Class Mode
call 4 -none- call
type 1 -none- character
predicted 60 factor numeric
err.rate 1500 -none- numeric
confusion 6 -none- numeric
votes 120 matrix numeric
oob.times 60 -none- numeric
classes 2 -none- character
importance 4 -none- numeric
importanceSD 0 -none- NULL
localImportance 0 -none- NULL
proximity 0 -none- NULL
ntree 1 -none- numeric
mtry 1 -none- numeric
forest 14 -none- list
y 60 factor numeric
test 0 -none- NULL
inbag 0 -none- NULL
xNames 4 -none- character
problemType 1 -none- character
tuneValue 1 data.frame list
obsLevels 2 -none- character
param 0 -none- list iristest_2levels<-irisTest%>%
filter(Species!="setosa")
IrisRF_Pred<-predict(IrisRF,iristest_2levels,type="prob")
irisrftestpred<-cbind(IrisRF_Pred,iristest_2levels)
rocobj<-pROC::roc(factor(irisrftestpred$Species), irisrftestpred$versicolor)
rocobj
Call:
roc.default(response = factor(irisrftestpred$Species), predictor = irisrftestpred$versicolor)
Data: irisrftestpred$versicolor in 20 controls (factor(irisrftestpred$Species) versicolor) > 20 cases (factor(irisrftestpred$Species) virginica).
Area under the curve: 0.9725plot(rocobj, colorize=T)
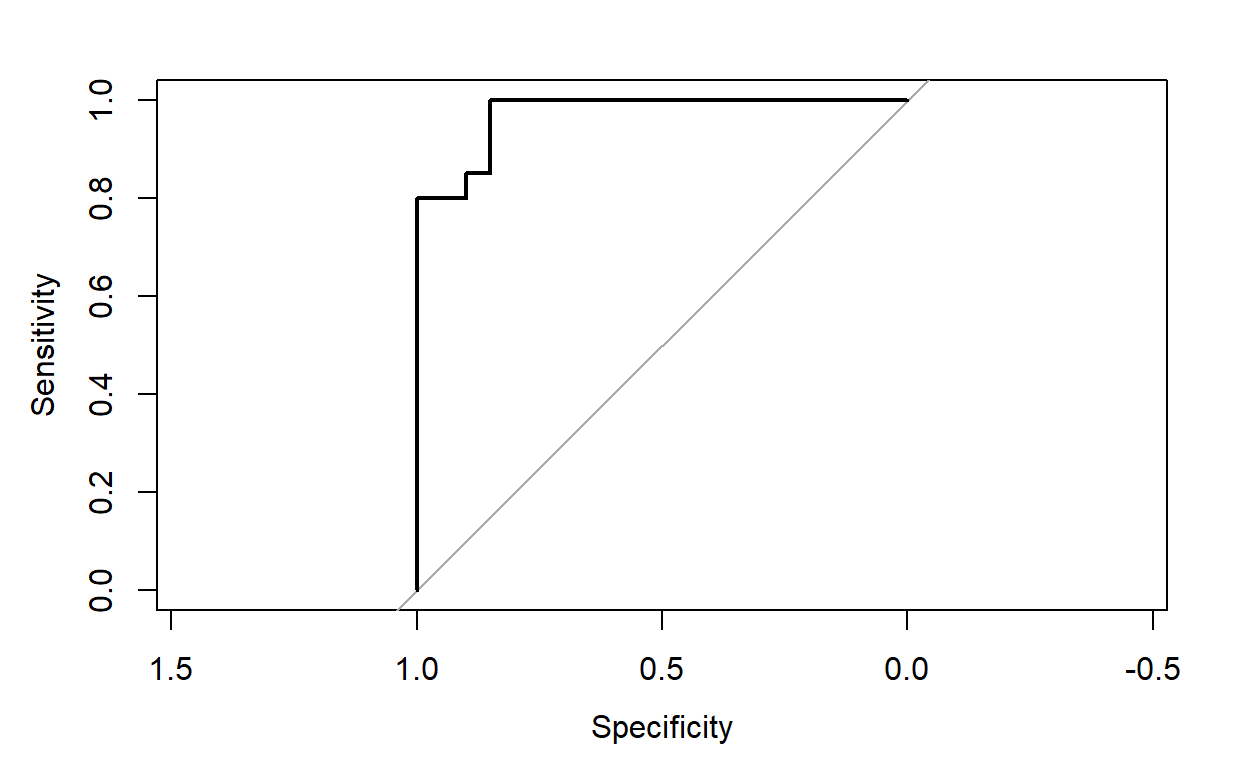
pred<-ROCR::prediction(irisrftestpred$versicolor ,factor(irisrftestpred$Species))
gain <- ROCR::performance(pred, "tpr", "rpp")
plot(gain, main = "Gain Chart")
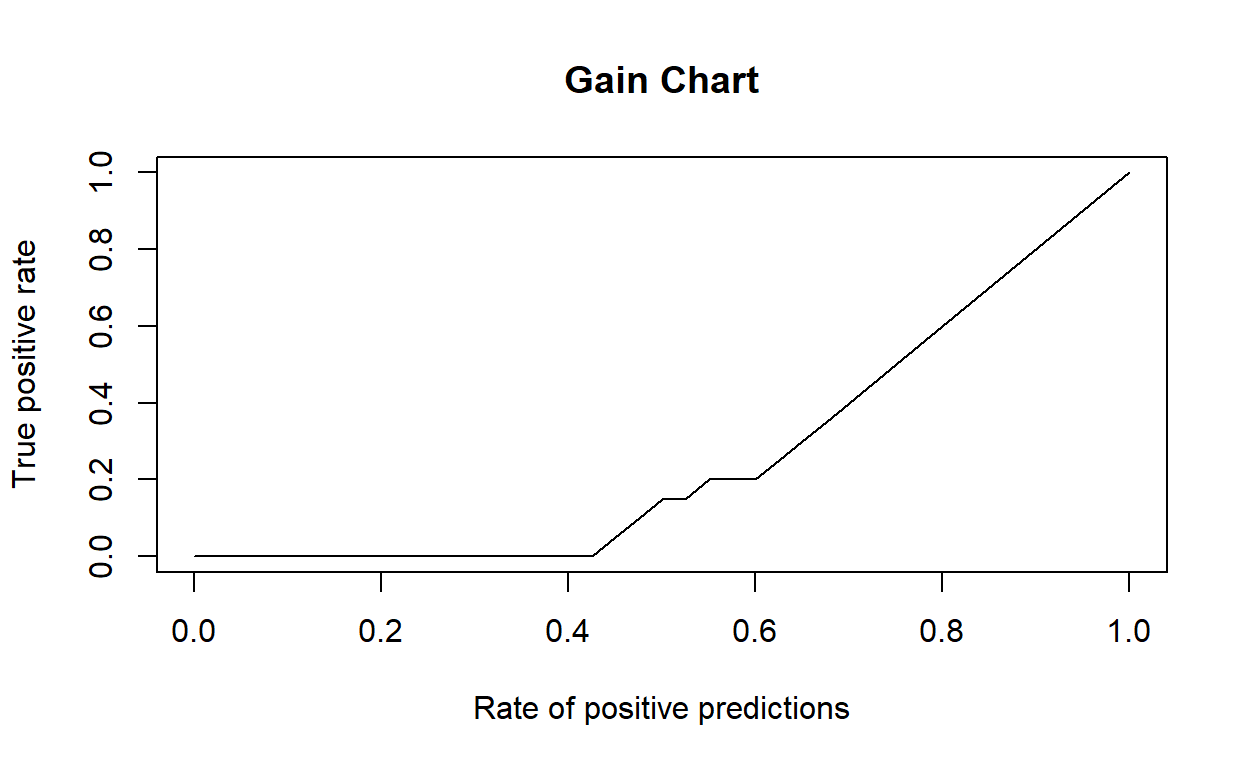
perf <- ROCR::performance(pred,"lift","rpp")
plot(perf, main="Lift curve")
fin